今日头条推荐算法原理及详解,今日头条的核心技术细节是什么?
阅读内容的原始积累。
今日头条核心算法负责人杨震原,之前就在在 MindStore 分享时提到,一开始今日头条的推荐算法,首先入手的是“非个性化推荐”——解决的热门文章推荐,以及新文章冷启动的问题。杨震原在“MindTalk 线场”说,“单纯的热门(文章),会让一些新文章没有机会。单纯的随机(推荐),(文章)质量当然不好,所以考虑一些简单方法,比如算一下威尔逊置信区间,来平衡热与新的问题。”之后,今日头条开始逐步引入个性化推荐的策略。他们所采用的,是协同过滤(Collaborative Filtering)** + 基于内容推荐,直到今天依然构成今日头条推荐算法的基础。
除此之外,今日头条还通过用户对内容的“正负反馈”来判断内容匹配是否精准。正反馈,包括用户点击了、看了很长时间、分享了、收藏了、评论了,都是正反馈。负反馈反而是比较难获取的,现在今日头条在内容上设置了一个小叉,点击之后,会咨询用户不感兴趣的理由,这种做法则会获取比较强的负反馈。但是通过这种方式收集到的数据还不多。
拿捏新闻推荐的平衡点,是整个业界都在钻研的问题。
通过杨震原的解释,我们基本知道了今日头条推荐算法的原理:通过算法,一边提取内容的特征,一边提取用户兴趣的特征,然后让内容与用户的兴趣匹配。
今日头条的个性化推荐不靠人、靠技术推荐时会兼顾用户、环境和文章本身特征这点可以看做他很好的一个技术壁垒。在个性化推荐这块还是考虑得因素蛮多的。
今日头条的推荐算法,相信是做自媒体朋友最为关心的吧,就在前不几的头条大会上,今日头条资深架构师曹欢欢首次公开揭秘。
1月11日,今日头条在总部举办了一场推荐算法交流会,因为报名人数远远超过了预期,交流会还临时换了场地。
冷启动(新用户首次使用)是否可以通过第三方数据来避免推荐不准?算法应该如何平衡广告内容和资讯内容?推荐的“准”和信息茧房的矛盾,应该如何协调?
今日头条公开算法的基本原理,并接受建言,体现出了一家平台对技术发展的责任感与诚意,这将对算法应用乃至整个互联网行业,起到巨大的积极推动作用。

今日头条副总编辑徐一龙
会议由今日头条副总编辑徐一龙主持。徐一龙在谈到今日头条对行业公开、透明自己算法原理的初衷时说,算法也是一种“法”,都是通过一定的规则和方法,达成预期的一种效果。算法和法律法规一样,如果施行的好,都很高效,也都要求透明。
曹欢欢博士在现场分享了今日头条推荐算法的基本原理,并详细介绍了算法模型设计维度与策略。包括如何在线训练大规模推荐模型,典型召回策略的设计方法,多目标如何融合等核心问题。此外,他还重点讲解了今日头条的内容安全机制及相关举措,公开了风险内容识别技术以及泛低质内容识别技术。
他表示:“算法分发并非是把所有决策都交给机器,我们会不断纠偏,设计、监督并管理算法模型。希望这次分享能让更多的人理解算法,并共同参与到算法模型的制定中来,以改善算法,更好的为用户服务,让算法为社会创造更大的价值。”

现场观众
此次今日头条将算法透明化,并接受建言,属于行业首例。算法原则历来属于公司行业机密,极少有公司会对外公布。今日头条方面表示,人工智能发展带来的挑战,是人类此前没有遭遇过的。当企业发展壮大时,有责任也有义务,与行业一道积极思考与研究新技术可能带来的机遇和风险。
据介绍,阿里、腾讯、百度、美团、新浪、网易等科技公司的算法工程师和产品经理都去了。看来大家对今日头条到底用了什么推荐算法,那是相当的好奇。
在当天的交流会上,今日头条资深算法架构师、中国科学技术大学计算机博士曹欢欢带来了题为《让算法公开透明》的分享,首次面向行业公开算法原理。

今日头条资深算法架构师曹欢欢讲解今日头条算法原理
他表示:“算法分发并非是把所有决策都交给机器,我们会不断纠偏,设计、监督并管理算法模型。希望这次分享能让更多的人理解算法,并共同参与到算法模型的制定中来,以改善算法,更好的为用户服务,让算法为社会创造更大的价值。”
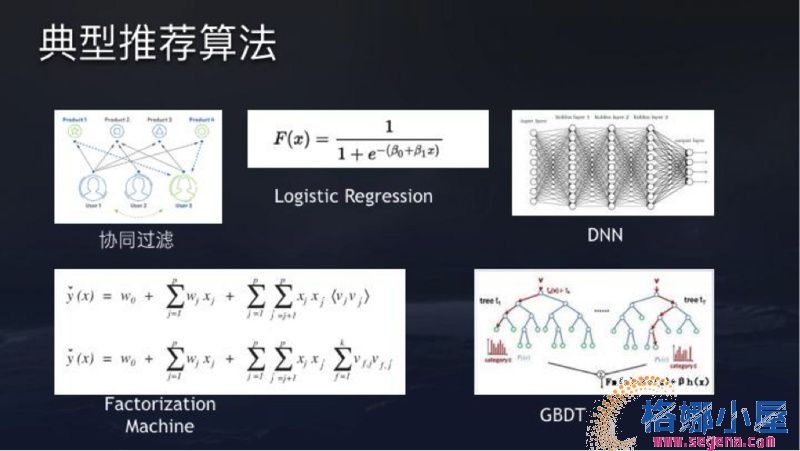
据曹欢欢介绍,今日头条旗下几款产品都在沿用同一套大的算法推荐系统,但根据业务不同,每套系统的架构会有所调整。 曹欢欢在现场的PPT里公布了头条使用的五种推荐算法,包括传统的协同过滤模型,监督学习算法Logistic Regression模型,基于深度学习的Factorization Machine,以及DNN和GBDT。 曹欢欢介绍说,现在很难有一套通用的架构模型适用于所有的推荐场景,所以很多公司会做多个算法的组合,比如现在很流行将LR和DNN结合,甚至前几年Facebook也是将LR和GBDT算法做结合。今日头条也基本是一套大算法,根据业务不同再具体调整结构。 在解释了算法之后,曹欢欢进一步解密了头条的推荐如何工作。曹欢欢表示,主要有四类最重要的用户特征,将会输入给算法,影响到推荐算法的工作。

第一类是相关性特征,就是评估内容的属性和维度与用户是否匹配。显性的匹配包括关键词匹配、分类匹配、来源匹配、主题匹配等。像FM模型中也有一些隐性匹配,从用户向量与内容向量的核心距离可以得出。 第二类是环境特征,包括地理位置、时间。这些既是bias(基础)特征,也能以此构建一些匹配特征。 第三类是热度特征。包括全局热度、分类热度,主题热度,以及关键词热度等。热度信息在大的推荐系统特别在冷启动的时候非常有效。 第四类是协同特征,它可以在部分程度上帮助解决所谓算法越推越窄的问题。协同特征并非考虑用户已有历史。而是通过用户行为分析不同用户间相似性,比如点击相似、兴趣分类相似、主题相似、兴趣词相似,甚至向量相似,从而扩展模型的探索能力。
分享过后,曹欢欢在还解答了各位对算法的疑问,包括今日头条如何实现冷启动,广告和内容该怎样平衡,怎样准确地拓展用户兴趣图谱等切实的工程性问题。同时,也听取了大家对今日头条算法的意见和建议。
更多,今日头条产品总监解密今日头条算法推荐原理(网友整理的笔记),https://note.youdao.com/share/?id=43aa778bef1fab276da7ffd8815ac91a
- 我的微信
- 这是我的微信扫一扫
-

- 我的微信公众号
- 我的微信公众号扫一扫
-





